

LLM Redash Chatbot
LLM based chatbot for Advanced Data Analytics, Visualisation, and Automated Insight Extraction

Transforming BI with our Redash Add-On
In the ever-evolving landscape of business intelligence, the need for advanced data analysis capabilities has become more apparent than ever. Recognizing this imperative, our company is embarking on an exciting journey to revolutionize data analytics through the development of a groundbreaking Redash add-on.
Our vision extends beyond traditional BI platforms, aiming to create a seamless integration that not only enhances the frontend experience but also introduces an intelligent backend capable of translating user queries into actionable insights. This multifaceted project encompasses the generation of summaries for visualizations in existing dashboards, insights derived from current SQL queries, and the automatic creation of SQL queries, visualizations, and entire Redash dashboards.
At the heart of this innovation is the bridge we are building between natural language and complex SQL queries. Our goal is to democratize data analytics, making it accessible to team members with non-technical backgrounds. By facilitating a smooth connection between users and their data, we aspire to streamline analytical processes, promoting efficiency, user-friendliness, and, ultimately, informed strategic decision-making.
Join us on this transformative journey as we unveil a tool that not only simplifies data exploration but also paves the way for a new era of accessible and empowering data analytics.
Understanding Data Analytics
Before delving into the intricacies of Large Language Models (LLMs) and their role in analytics, let’s establish a clear understanding of what data analytics entails and the tasks performed by analysts.
At the core of our analytical mission is the commitment to aiding product teams in making informed decisions based on available data within a given timeframe. To further refine the scope of LLM-powered analysts, we turn to the comprehensive framework proposed by Gartner, which identifies four distinct Data and Analytics techniques.
- Descriptive Analytics: This technique addresses the question, “What happened?” It involves reporting tasks and working with Business Intelligence (BI) tools to, for instance, determine the revenue in a specific month.
- Diagnostic Analytics: Moving beyond descriptive analytics, this technique seeks answers to questions like, “Why did something happen?” Analysts engaged in diagnostic analytics delve into detailed data analysis, employing drill-down and slicing & dicing techniques. For example, they may investigate why revenue decreased by 10% compared to the previous year.
- Predictive Analytics: This technique provides insights into the future, answering questions such as, “What will happen?” Forecasting and simulation are the cornerstones of predictive analytics, enabling businesses to anticipate outcomes under various scenarios.
- Prescriptive Analytics: Shaping final decisions, prescriptive analytics tackles questions like, “What should we focus on?” or “How could we increase volume by 10%?” This technique guides strategic decision-making based on analyzed data.
Companies typically progress through these analytical stages sequentially, reflecting their data maturity. Similarly, analysts evolve from junior to senior levels, traversing these stages from well-defined reporting tasks to addressing complex strategic inquiries.
In the context of LLM-powered analysts, our initial focus is on descriptive analytics and reporting tasks. Mastery of these fundamentals is crucial before delving into predictive and prescriptive analytics. This strategic approach aligns with the natural progression of both companies and individual analysts, ensuring a solid foundation for advanced analytical tasks.
LLM & data analysis
Large Language Models (LLMs) are advanced artificial intelligence models designed to comprehend and generate human-like text based on extensive language training datasets. In the realm of data analysis, LLMs play a pivotal role by bridging the gap between complex queries and natural language.
These models are instrumental in enhancing descriptive analytics and reporting tasks, enabling analysts to extract meaningful insights from data through intuitive and language-driven interactions. By leveraging LLMs, data analysts can streamline their workflow, starting from foundational tasks and gradually progressing to more sophisticated analytical challenges. This integration of LLMs into data analysis signifies a paradigm shift, making analytics more accessible, efficient, and user-friendly, ultimately empowering organizations to make well-informed decisions based on their data.
What’s Redash?
Redash is designed to enable anyone, regardless of the level of technical sophistication, to harness the power of data big and small. SQL users leverage Redash to explore, query, visualize, and share data from any data sources. Their work in turn enables anybody in their organization to use the data. Every day, millions of users at thousands of organizations around the world use Redash to develop insights and make data-driven decisions. Redash features:
- Browser-based: Everything in your browser, with a shareable URL.
- Ease-of-use: Become immediately productive with data without the need to master complex software.
- Query editor: Quickly compose SQL and NoSQL queries with a schema browser and auto-complete.
- Visualization and dashboards: Create beautiful visualizations with drag and drop, and combine them into a single dashboard.
- Sharing: Collaborate easily by sharing visualizations and their associated queries, enabling peer review of reports and queries.
- Schedule refreshes: Automatically update your charts and dashboards at regular intervals you define.
- Alerts: Define conditions and be alerted instantly when your data changes.
- REST API: Everything that can be done in the UI is also available through REST API.
- Broad support for data sources: Extensible data source API with native support for a long list of common databases and platforms
Project Blueprint
1. Foundation, Tool Familiarization, and NLP Enhancement
Objective: Establish foundational chatbot capabilities and enhance NLP for accurate SQL translations while gaining a deep understanding of key LLM developments and tools.
Implementation:
- Utilize Python, OpenAI API, and LangChain for initial language understanding and SQL translation.
- Familiarize with OpenAI tools, LangChain components, LLamaIndex, and Vector Databases.
- Review relevant links and summarize findings in a comprehensive report.
- Embed LangChain into the Python backend for advanced NLP, replacing basic OpenAI API usage.
2. Advanced Data Handling and Semantic Search
Objective: Optimize data management for efficient retrieval and processing, incorporating semantic search capabilities using Vector Databases.
Implementation:
- Implement LLamaIndex to streamline data access and integrate various data sources.
- Utilize vector databases for storing and searching transcribed text, comments, and metadata from YouTube.
- Explore embedding documents and semantic search using vector similarity.
3. Tool Understanding, Redash Integration, and Dashboard Development
Objective: Understand Redash’s capabilities, connect to data sources, and develop a user-friendly dashboard interface.
Implementation:
- Learn Redash for data visualization and analytics.
- Design an efficient YouTube data schema considering channel performance, user base, and video expenses.
- Outline the architecture for the Redash add-on and backend systems.
- Develop the dashboard interface with React for a user-friendly experience.
- Develop a backend system for data storage and processing using Quart (async version of Flask).
4. LLM Integration and Automatic Dashboard Generation
Objective: Integrate language models for natural language understanding and automate visualization generation based on user queries.
Implementation:
- Incorporate language models for interpreting and processing natural language queries.
- Integrate the add-on to convert natural language queries into SQL, ensuring compatibility with Redash.
- Implement OpenAI Actions (previously called Plugins) for seamless integration.
- Experiment quickly using Flowise AI for rapid testing and improvement.
- Implement automatic visualization generation based on user queries and existing context.
This consolidated plan provides a seamless and cohesive approach to developing an advanced chatbot system, integrating language models, data handling, semantic search, and user-friendly visualization.
Methodology
Enabling Seamless Collaboration
For our collaborative team project, we took the essential step of setting up a GitHub organization to streamline our version control and collaboration efforts. Within this organization, we established a shared repository to facilitate seamless teamwork and code management.
To support our data storage needs and ensure a centralized and accessible database for the entire team, we opted for a PostgreSQL database hosted on Render. This decision allows us to have a shared and scalable database infrastructure, enhancing collaboration and data consistency across the team. The Render platform provides a reliable environment for our PostgreSQL database, aligning with our project’s collaborative nature and data management requirements.
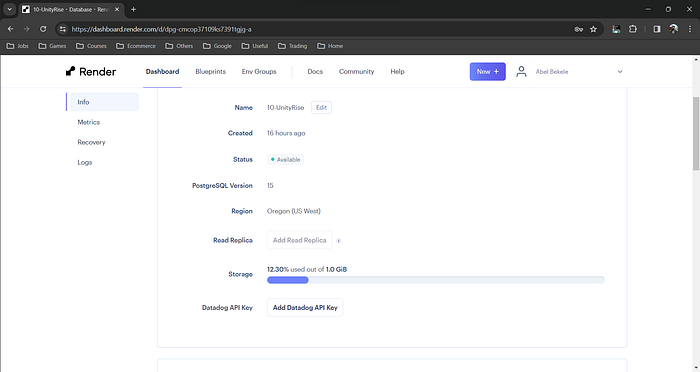
Postgres database hosted on render
Creating virtual machine
The project initiation commenced by establishing a dedicated virtual machine, a crucial component for achieving a production-ready setup through comprehensive Dockerization. Utilizing the robust Proxmox virtualization platform within the home lab, a virtual machine was configured with substantial resources: 4 CPU sockets, 4GB of RAM, and a capacious 64GB hard disk. This thoughtful allocation ensures optimal performance and scalability, forming the basis for a seamlessly Dockerized environment. Following the virtual machine setup, Debian 12 (Bookworm) was installed as the operating system, providing a robust foundation for subsequent phases in the development and deployment of this exciting project.
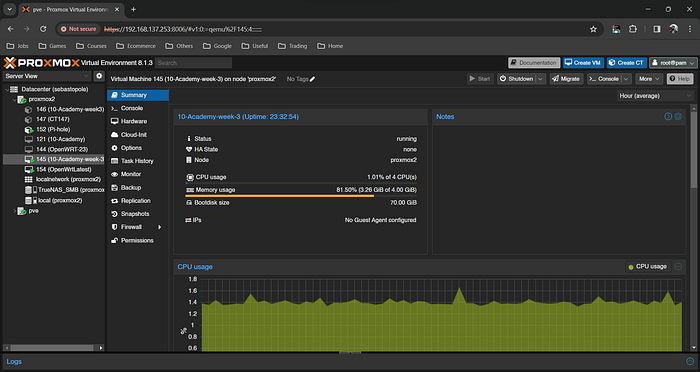
Proxmox running a debian vm
Redash Local development setup
Embarking on Redash development opens up a world of possibilities, and the first crucial step is establishing a robust local environment. Whether on Linux or Windows WSL2, the process involves installing essential packages for Docker, NodeJS, and Yarn. With the Redash source code cloned, dependencies installed, and local environment variables generated, developers seamlessly compile the front end and build a local Redash Docker image. Starting Redash locally becomes effortless, and accessing the web interface at http://localhost:5001 marks the gateway to configuration. Python setup for backend development follows suit, ensuring compatibility with various data sources. This holistic overview sets the stage for a smooth Redash development journey. For detailed steps, check out the comprehensive guide here.
Redash login page after setup
Dataset
Our YouTube channel data is a treasure trove, encompassing video metadata such as titles and upload dates, time series viewership metadata revealing performance trends, and time-stamped comments fostering community engagement analysis. Transcribed text aids content analysis and SEO, while the data snapshot offers real-time metrics for strategic refinement and audience engagement enhancement.
Within each folder of our diverse data sources, a trio of CSV files acts as a gateway to profound insights in our YouTube ecosystem. Whether it’s the platforms in Sharing service, Viewer age demographics, or geographic distribution in Cities, each source contributes to our content narrative. Subscription status and New and returning viewers reveal audience commitment and retention, while Geography unveils our global viewership.
Device type and Operating system dive into the technical landscape, and Viewer gender enriches audience demographics. Subtitles and CC enhance inclusivity, Content type categorizes genres, Subscription source uncovers subscriber origins, and Traffic source identifies discovery channels. Viewership by Date adds a temporal dimension, completing a comprehensive mosaic of our YouTube presence with the insights contained in three CSV files within each folder.
Creating a database schema to load data
To consolidate and organize our YouTube analytics, we devised a structured database schema. Within each CSV file in every folder, a unique locking column was employed to synchronize and merge the data seamlessly. Leveraging this approach, we facilitated a cohesive integration of insights. The data was then systematically pushed into the database, with the nomenclature of each folder serving as the distinctive table name. This meticulous schema design streamlined the amalgamation process, ensuring a unified and accessible repository for our comprehensive YouTube analytics.
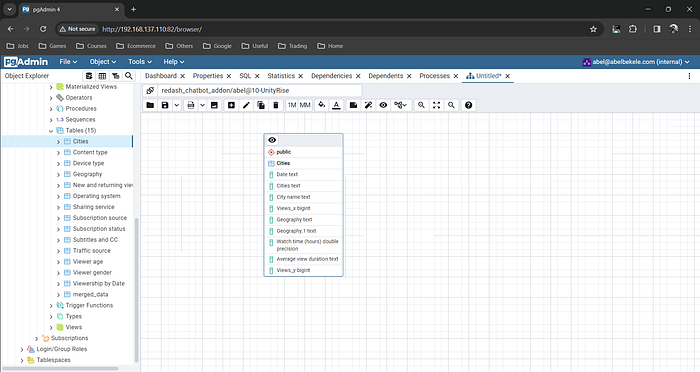
Pgadmin showing the schema of one table
Adding the chatbot to redash
In the intricate construction of the Redash chatbot, attention was dedicated to both the frontend and backend components. Drawing upon the robust Redash source code, the frontend was meticulously crafted using React.js, allowing for the creation of dynamic and responsive components. Complementing this, the styling was honed with Less CSS, adding an extra layer of sophistication to the user interface.
On the backend, the Flask framework was selected for its versatility and reliability. This choice provided a sturdy foundation for handling the intricacies of the chatbot's functionality, ensuring seamless execution of complex operations. The critical interplay between the frontend and backend was meticulously facilitated by the integration of Axios, a powerful HTTP client, to enable efficient communication and data exchange.
Flask Teams Up with OpenAI GPT-3.5 Turbo
Embarking on a journey to infuse intelligence into database interactions, I recently achieved a seamless integration of Flask and OpenAI’s GPT-3.5 Turbo. This fusion delivers a dynamic assistant capable of not only analyzing PostgreSQL databases but also generating SQL queries on-the-fly. Here’s a snapshot of this transformative integration:
Connecting the Dots: Flask & Database Schema
Flask takes center stage by establishing a secure connection to a PostgreSQL database. This not only ensures a robust foundation for database interaction but also includes a smart schema retrieval mechanism, fetching table and column names for a comprehensive understanding.
OpenAI Magic: GPT-3.5 Turbo Unleashed
Enter the GPT-3.5 Turbo from OpenAI, seamlessly woven into the Flask application. With API keys securely in place, this model becomes the brain behind dynamic conversations, responding intelligently to user queries and generating SQL queries based on contextual input.
Chat-Driven SQL Queries: Where Conversations Shape Code
User queries trigger a dance of conversations with the GPT model, resulting in the intelligent generation of SQL queries. The assistant not only interprets user inquiries but crafts SQL syntax dynamically, offering contextual responses that go beyond mere automation.
Redash Queries on the Fly: Crafting Intelligence
The ChatResource class takes charge, efficiently crafting Redash queries dynamically. This enables the assistant to generate queries with specific options, responding in real-time to user needs.
Designing for Resilience: Robustness in Action
To ensure a reliable and resilient system, robust error handling takes the spotlight. Leveraging tenacity’s retry mechanism, the implementation stands prepared to gracefully handle potential API or database hiccups.
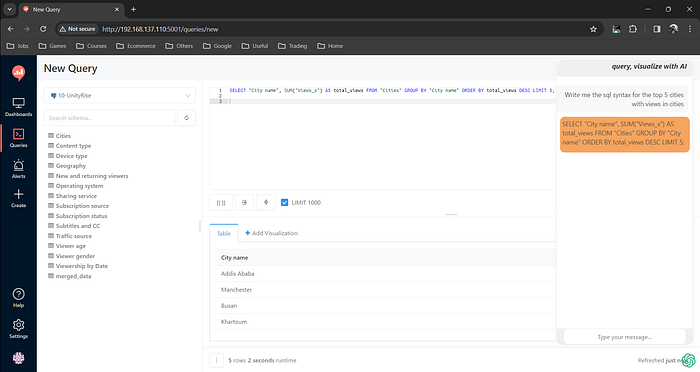
Redash and React Client API for Automated Dashboards and SQL Generation
In the realm of data-driven decision-making, the fusion of Redash and a robust React Client API opens a gateway to effortless dashboard creation and dynamic SQL query generation. Let’s explore how this powerful integration can redefine your data visualization workflows.
The RedashAPIClient
At the heart of this synergy is the RedashAPIClient. With your API key and Redash host, this client becomes your conduit for seamless communication, setting the stage for a plethora of actions.
redash_client = RedashAPIClient(api_key=”your_api_key”, host=”http://localhost:5000")
Creating Intelligent Data Sources:
Creating Intelligent Data Sources
Effortlessly generate data sources with the create_data_source method. Define the type, name, and additional options to tailor the source to your unique requirements.
redash_client.create_data_source(_type=”your_type”, name=”your_data_source_name”, options={“your_option”: “option_value”})
Dynamic Querying and Refreshing
Interact dynamically with your queries. Trigger a query refresh or generate query results on the fly using the refresh_query and generate_query_results methods.
redash_client.refresh_query(qry_id=your_query_id)
redash_client.generate_query_results(ds_id=your_data_source_id, qry=”your_query_string”)
Elevating Visualizations
Supercharge your dashboards with visually appealing charts and tables. The create_visualization method supports a variety of visualization types, from line charts to pivot tables.
redash_client.create_visualization(qry_id=your_query_id, _type=”your_visualization_type”, name=”your_visualization_name”, columns=[…], x_axis=”your_x_axis”, y_axis=[…], size_column=”your_size_column”, group_by=”your_group_by”, custom_options={“your_custom_option”: “option_value”}, desc=”your_description”)
Streamlining Dashboard Management
Simplify dashboard creation and widget addition with the create_dashboard, add_widget, and calculate_widget_position methods. Fine-tune your dashboard’s appearance and effortlessly publish it.
redash_client.create_dashboard(name=”your_dashboard_name”)
redash_client.add_widget(db_id=your_dashboard_id, text=”your_widget_text”, vs_id=your_visualization_id, full_width=True, position={“your_position_option”: “option_value”})
redash_client.calculate_widget_position(db_id=your_dashboard_id, full_width=True)
redash_client.publish_dashboard(db_id=your_dashboard_id)
This integration of Redash and React Client API redefines the landscape of data visualization and query generation. From creating intelligent data sources to crafting dynamic dashboards, this API duo simplifies the process, offering a potent tool for developers and data enthusiasts alike.
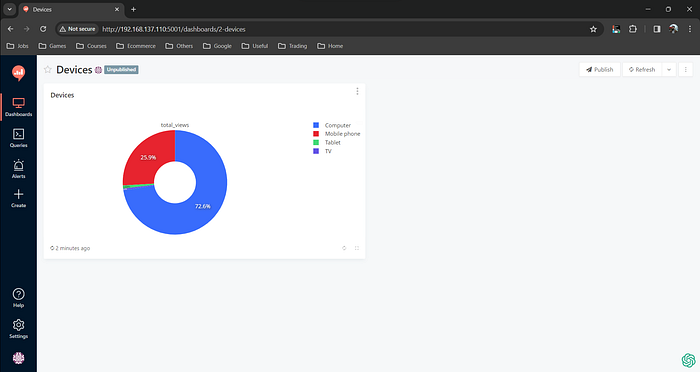
Challenges faced
Embarking on the journey to build a Redash-integrated chatbot brought forth a series of challenges that tested our team’s skills and resilience. In this blog post, we’ll delve into the three key challenges encountered during the development process, with a particular focus on using the RedashAPI client to create datasources, queries, and dashboards.
Local Deployment and Integration
The initial hurdle was the need to build Redash locally and seamlessly integrate it with our chatbot. This demanded a meticulous approach to ensure a flawless fusion of the two components. Overcoming compatibility issues and ensuring a smooth user experience were paramount. With the added challenge of using the RedashAPI client to establish connections, create datasources, and integrate them effectively, our team navigated through this complexity, demonstrating our capability to harness powerful tools for a cohesive solution.
Robust Database Schema Design
Designing a database schema capable of accommodating diverse datasets without compromising on values and relationships presented the second major challenge. Striking a balance between comprehensive data storage and maintaining integrity required a thoughtful and strategic approach. Our team not only tackled this challenge by leveraging the RedashAPI client to create queries that efficiently interacted with the database but also seamlessly integrated them into our chatbot, ensuring a dynamic and responsive user experience.
OpenAI API Integration
The third challenge emerged in the form of integrating the OpenAI API within a limited timeframe. Understanding the intricacies of the API and implementing it effectively demanded rapid comprehension and precise execution. Grasping the capabilities of OpenAI and applying them with the right methodology were crucial for the success of our project. The use of RedashAPI client to create dashboards further enhanced our ability to visualize and interpret OpenAI-powered insights, adding an extra layer of complexity that we successfully navigated.
Conclusion
In the realm of developing a Redash-integrated chatbot, challenges are inevitable. However, it is through overcoming these challenges that true innovation and progress emerge. Our journey was marked by the triumphant resolution of challenges, including the effective utilization of the RedashAPI client for creating datasources, queries, and dashboards. Each obstacle served as an opportunity to learn, grow, and ultimately deliver a sophisticated and functional product. As we reflect on our experiences, we are reminded that the path to innovation is often paved with challenges that, when faced head-on, lead to success and accomplishment.
Lessons Learned
Adaptability is Key
The journey reinforced the importance of adaptability in the face of unforeseen challenges. Our ability to pivot, reassess, and adapt our strategies was crucial in overcoming hurdles, ensuring that we stayed on course despite unexpected twists in the development process.
Collaborative Problem-Solving
Challenges are best approached as a team. Collaborative problem-solving not only brings diverse perspectives to the table but also fosters a culture of shared responsibility. Our success in resolving complex issues was a testament to the strength of collective intelligence within our team.
Strategic Planning Mitigates Risks
While challenges are inevitable, strategic planning and foresight can mitigate potential risks. Proactively identifying and addressing potential roadblocks allowed us to navigate the development process more smoothly, reducing the impact of unforeseen challenges.
Limitations
Scalability
The project may face challenges in scalability, especially when dealing with a large volume of concurrent user requests. As the user base grows, the system might experience performance issues, and optimizing for scalability would be a critical consideration.
Compatibility with Diverse Data Sources
Ensuring compatibility with a wide range of data sources is complex. Future developments should consider addressing issues related to data source integration, ensuring smooth interactions with various databases and platforms.
Prompt-Specific History
The current implementation might lack a robust history-saving feature within individual prompts or chat sessions. Users may find it challenging to revisit or reference specific interactions within a session, limiting their ability to track the evolution of queries or insights during a conversation.
Future Plan
Prompt-Specific History Logging
Implementing a history-saving mechanism within the prompts or chat sessions would be crucial. This feature could allow users to review and navigate through the history of their interactions, providing a context-aware view of the conversation. Users should be able to refer back to earlier prompts, queries, and responses within the same session.
Searchable History
Enhance the history-saving feature by making it searchable. Users should have the capability to search for specific terms or keywords within the prompt-specific history, facilitating quick access to relevant parts of the
Machine Learning Integration:
Integrate machine learning algorithms to allow the system to learn from user interactions and feedback. This could enhance the system’s ability to adapt to user preferences and provide more personalized insights over time.
Newsletter
If you liked this post, sign up to get updates in your email when I write something new! No spam ever.
Subscribe to the Newsletter